HTTP/2とは何か?
カリキュラムを進めていく上で、HTTPのバージョンに触れていたので
それについて少し調べてみた。
HTTP/2とは、閲覧してるページのデータをWEBサーバーから取得する際の
新しいプロトコルである。
HTTP/2とは?HTTP/1.1との違い
ここでは、ウェブサーバーからウェブページのデータを取得するためのプロトコルとして現在よく使われているHTTP/1.1とHTTP/2の違いを紹介します。そのうえで、なぜHTTP/2が誕生したのか、その経緯についてもくわしく解説します。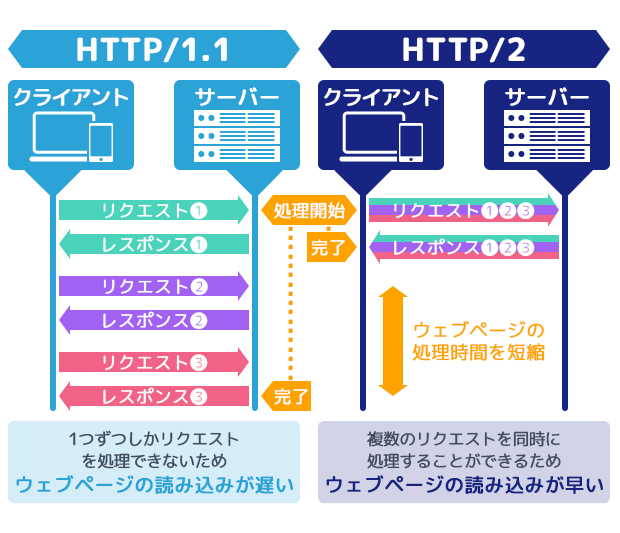
従来使われてきたHTTP/1.1では、ウェブサーバーに対して原則1つずつしかリクエストを送ることができません。たとえばウェブページに表示する画像が2つあったとして、1つ目の画像を読み込み終わってから、ようやくもう1つの画像を読み込み始めるということです。
一方、新しく登場したHTTP/2では、複数のリクエストを同時に処理することができます。先ほどの例にあてはめると、仮にウェブページに2つの画像があれば、その2つを同時に読み込むことができるわけです。これにより通信の効率が改善し、ウェブページの読み込みが早くなります。
より専門的に説明すると、HTTP/1.1でもウェブサーバーに対して同時に複数のリクエストを行うことは可能です。ただしリクエストされた順番通りに、1つずつしかリクエストを処理できないという問題がありました。結果、複数のリクエストがあった場合に、前のリクエスト処理が遅いと、2番目以降のリクエストの処理が待ち状態となり結果的にウェブページの表示速度も遅くなってしまいます。
HTTPの変化と歴史
ここでは、ウェブサーバーからウェブページのデータを取得するHTTPというプロトコルにおいて、どのような変遷をへてHTTP/2が生まれたのか、その歴史を簡単に振り返ります。
このように1991年に公開されたのち、複雑化するウェブページに合わせHTTPは改良がおこなわれてきました。2015年に公開されたHTTP/2はより効率よくリクエストの処理ができるようになっており、表示速度の改善され、スムーズウェブページを見ることができると期待されています。
HTTP/2のメリットと課題
HTTP/2を導入することで通信が効率化され、結果的にウェブページの読み込み速度が向上するといったメリットがあります。ただしHTTP/2に課題がないわけではありません。
まずGoogle ChromeやFirefoxといった主要なブラウザでは、TLSによる暗号化が行なわれたHTTPSの通信上でしかHTTP/2が使えない点に注意が必要です。HTTP/2自体はHTTPの通信にも対応していますが、ブラウザの仕様によりHTTP/2を利用するなら結果的にHTTPSへの対応も必要となるのです。
また全てのサイトがHTTP/2で高速化されるわけではありません。たとえば、もともとコンテンツが少ないサイトでは、せっかくHTTP/2へ対応させても目に見える効果は期待しにくいでしょう。
それからコンテンツを複数ドメインに分散して保存しているウェブページでは、同一ドメインのサーバーに対し複数のリクエストを処理するというHTTP/2のメリットを十分に活かせません。(複数ドメインにコンテンツを分散する手法を、ドメインシャーディングと呼びます。)この場合も、HTTP/2で期待するほどの成果が出せない可能性があります。
HTTP/2が向いているウェブサイトとは
まず、HTTPSによる暗号化に対応したウェブサイトであることが必要です。またコンテンツが1つのドメインのサーバーに集約されているウェブサイト、コンテンツ量が多いウェブサイトは、HTTP/2によって効果を期待できるでしょう。
機能が増え、効率を上げたのがHTTP/2
それまでのHTTP/1.1と比較して、ウェブサイトの表示速度向上を期待できるのがHTTP/2です。HTTP/2では、複数のリクエストを同時に処理できるようになるなど、昨今のウェブサイトが抱える大量のコンテンツを効率的に送受信できる機能が複数追加されていますので是非利用してみてください。ただし、主要ブラウザの仕様の関係で、TLSによってHTTPSで暗号化されたウェブサイトでしかHTTP/2が使えないなどの課題があり、全てのウェブサイトで採用できるわけではない点には注意が必要です。
jQueryにおいて<ul>要素に<li>要素を入れ子で入れる方法
プログラミングでよく使う括弧系の呼び名
ブログラミングで頻繁に使う3つの括弧 ( ) [ ] { } の呼び方が、自分の中でちゃんと定着してないので、ちょっと整理してみました。
特に { } が曖昧で、いっつもあの大きい括弧とか言っちゃうので、ちゃんと呼び方覚えたい。
| 括弧 | 使う呼び方 | その他の名称 |
| () | 丸括弧 | 丸括弧、パーレン、parenthesis |
| [] | ブラケット | 角括弧、ブラケット(bracket) |
| {} | 波括弧 | 波括弧、ブレイス(brace)、カーリーブラケット(curly bracket)、カール(curl) |
ブラケットは、いつの間にかそれで覚えてしまったというのもあるけど、角括弧って呼び方もそんなに定着していない気がする。
丸括弧は、これはわざわざカタカナを使う必要は無いくらい丸括弧。
波括弧は、ちょっと悩ましくて、波括弧でもあまり定着していない気がするけど、ブレイスとかカールとか言われても通じないと思う。
ともあれ、波括弧ってちゃんと呼ぶように気をつけたい。
パソコンは16進数を好む
位取り記数法とは
数は十種類の文字(0,1,2,3,4,5,6,7,8,9)で表現する。
何もなければ「0」、一個なら「1」、二個なら「2」のように、数を意味する一文字を当てはめる。
| 0 | |
| ● | 1 |
| ●● | 2 |
| ●●● | 3 |
| ●●●● | 4 |
| ●●●●● | 5 |
| ●●●●● ● | 6 |
| ●●●●● ●● | 7 |
| ●●●●● ●●● | 8 |
| ●●●●● ●●●● | 9 |
| ●●●●● ●●●●● | 10 |
| ●●●●● ●●●●● ● | 11 |
| ●●●●● ●●●●● ●● | 12 |
十個以上になると、一文字で数を表すことができない。
そこで二つ以上の文字を組み合わせて数を表現する。(右表)
この方法は数が十倍になるたびに桁が増えていく。
だから、どんなに大きな数であっても、たった十種類の文字だけで表現できるのだ。
このように、桁を伸ばしていく数の表し方を位取り記数法という。
どんなに大きな数であっても、位取り記数法なら桁を増やすだけで対応化のだ。
もし、位どり記数法を使わなかったら、大きな数字を表すために字を用意しなくてはならない。
例えば、漢字がいい例である。
万、億、兆、京、垓、杼(本当はのぎへん)、穣、溝、澗、正、載、極・・・・
のように、より大きな数を表したければ、新たに文字を用意しなくてはならないのだ。
| 百 | 100 |
| 千 | 1000 |
| 万 | 10000 |
| 億 | 100000000 |
| 兆 | 1000000000000 |
| 京 | 10000000000000000 |
| 該 | 100000000000000000000 |
10進数と2進数
日常では十種類の文字(0,1,2,3,4,5,6,7,8,9)を位取り記数で利用する。
もし、使える文字が2種(0と1)しかなかったとしても、位取り記数法は同じように成立する。
| 十種で表現する場合 | 二種で表現する場合 | |
| (十進数) | (二進数) | |
| 0 | 0 | 0 |
| ● | 1 | 1 |
| ●● | 2 | 10 |
| ●●● | 3 | 11 |
| ●●●● | 4 | 100 |
| ●●●●● | 5 | 101 |
| ●●●●● ● | 6 | 110 |
| ●●●●● ●● | 7 | 111 |
| ●●●●● ●●● | 8 | 1000 |
| ●●●●● ●●●● | 9 | 1001 |
| ●●●●● ●●●●● | 10 | 1010 |
| ●●●●● ●●●●● ● | 11 | 1011 |
| ●●●●● ●●●●● ●● | 12 | 1100 |
十種類の文字を利用する位取り記数法を10進数、二種類の文字を利用する場合を2進数という。
日常で使う数字は10進数なのだ。
10進数で表現する場合は、十個以上で桁が増えた。
2進数を使ったときは2個以上で桁が増える。
桁が増えるタイミングが違うでだけで、10進数も2進数も、限定された文字数を使いまわして、大きな数を表そうという発想だ。
こうなると、使える文字の数を決めれば、5進数や8進数、4進数もあり得ることになる。
(実用的かどうかは別として)
16種類の文字を用意すれば、16進数を作ることができる。
16種類の文字のうち十種類は通常の数字(0〜9)、6種類はA〜Fまでのアルファベットを使用する。
| - | 10進数 | 2進数 | 16進数 |
| 0 | 0 | 0 | 0 |
| ● | 1 | 1 | 1 |
| ●● | 2 | 10 | 2 |
| ●●● | 3 | 11 | 3 |
| ●●●● | 4 | 100 | 4 |
| ●●●●● | 5 | 101 | 5 |
| ●●●●● ● | 6 | 110 | 6 |
| ●●●●● ●● | 7 | 111 | 7 |
| ●●●●● ●●● | 8 | 1000 | 8 |
| ●●●●● ●●●● | 9 | 1001 | 9 |
| ●●●●● ●●●●● | 10 | 1010 | A |
| ●●●●● ●●●●● ● | 11 | 1011 | B |
| ●●●●● ●●●●● ●● | 12 | 1100 | C |
| ●●●●● ●●●●● ●●● | 13 | 1101 | D |
| ●●●●● ●●●●● ●●●● | 14 | 1110 | E |
| ●●●●● ●●●●● ●●●●● | 15 | 1111 | F |
| ●●●●● ●●●●● ●●●●● ● | 16 | 10000 | 10 |
| ●●●●● ●●●●● ●●●●● ●● | 17 | 10001 | 11 |
| ●●●●● ●●●●● ●●●●● ●●● | 18 | 10010 | 12 |
指を折って数える動作と十進数は非常に相性がよい。
指の数が10本だからだ。
もし、日常生活で9進数や3進数を使うようになったら大変混乱することだろう。
人間が指を折って数える代わりに、コンピュータは電流が流れる、流れないという二種類の動作で数を扱う。
コンピュータは10進数よりも、二種類の数字しか使わない2進数との相性が優れているのだ。
ここで困ったことが起きる。
コンピュータを扱う技術者は、10進数ではなく2進数を使わなくてはならない。
例えば、「500」は「111110100」と書くことになる。
「500」の場合、3桁で済む数字も二進数では9桁で表すので、たまったものではない。
16進数と2進数の変換
そこで、コンピュータにとっては二進数のように扱え、人間にとっては短い桁で納まるような書き方が求められるようになった。
そのような都合のよい書き方が、16進数だ。
0〜Fの範囲で2進数と16進数の対応表を見てみよう。
| 2進数 | 16進数 | 10進数 |
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | A | 10 |
| 1011 | B | 11 |
| 1100 | C | 12 |
| 1101 | D | 13 |
| 1110 | E | 14 |
| 1111 | F | 15 |
この表を見ると、1桁の16進数が最大値Fのとき、4桁の2進数も最大値1111になることが分かる。
言い換えると、1桁の16進数を2進数に変換する場合、2進数はどんなに大きくても最大で4桁あれば十分ということだ。
二桁の16進数の最大値はFFで、2進数では11111111になる。(十進数では255)
この値は8桁の二進数の最大の値だ。
ここから2桁の16進数を2進数に変換する場合、2進数はどんなに大きくても最大で8桁あれば十分ということだ。
同様に考えると次のように考えることができる。
1桁の16進数→4桁の2進数で変換可能
2桁の16進数→8桁の2進数で変換可能
3桁の16進数→12桁の2進数で変換可能
n桁の16進数→(4×n)桁の2進数で変換可能
このことから、2進数と16進数は「4桁」をキーワードとして強い関連を持っていることが確認できる。
2進数を16進数に変換する場合、2進数を4桁ごとに区切れば簡単だ。
その区切りごとに対応表を見て16進数に置き換えればいい。
例えば、次の2進数があったとする。
11101011101000011011001110
人間にとっては長くて扱いにくい量だ。
これを4桁ごとに区切る。先頭は2桁なので00を付けて4桁にあわせよう。
| 0011 | 1010 | 1110 | 1000 | 0110 | 1100 | 1110 |
それぞれの4桁を、対応表を見ながら16進数に置き換えるのだ。
| 0011 | 1010 | 1110 | 1000 | 0110 | 1100 | 1110 |
| 3 | A | E | 8 | 6 | C | E |
区切りを外した値3AE86CEが、16進数となる。
対応表があれば簡単に変換できることが分かったと思う。
たった16個の対応さえ覚えてしまえば、対応表がなくても変換は可能だ。
Rubyにおける変数色々
Rubyにおける変数の種類
ほかに、疑似変数があるが本記事では省略。
ローカル変数
書き方:小文字または_ではじめる。
スコープ:(宣言した位置から)その変数が宣言されたブロック、メソッド定義、またはクラス/モジュール定義の終わりまで。つまり、オブジェクトの壁やメソッドの壁を超えては参照できず、それが定義された場所でしか通用しない、名前通り極めてローカルなもの。
sample.rb
code
試しに、内側から呼び出してみる。
sample.rb
class Harahe
my_feeling = "お腹へった!!"
def tabetai
puts my_feeling, "コンビニいこ" #tabetai内で定義されていないローカル変数を呼び出してみる
end
end
harahe = Harahe.new
harahe.tabetai #=>undefined local variable or method `my_feeling'
繰り返す。やはり、オブジェクトの壁やメソッドの壁を超えては参照できず、それが定義された場所でしか通用しない。
インスタンス変数
書き方 : @を前置する
スコープ:クラス内で全メソッドで共通して使用することが出来る。クラスから作成されるオブジェクト毎に固有のもの。このようにインスタンスごとに独立してもつ変数だから、インスタンス変数という。
sample.rb
class Harahe
def initialize(feeling)
@feeling = feeling
end
def gaman
puts @feeling,"・・・けど我慢しよ"
end
end
harahe = Harahe.new("お腹減った")
harahe.gaman #=>お腹減った!・・・けど我慢しよ
haraherinu = Harahe.new("腹へりぬ")
haraherinu.gaman #=>腹へりぬ・・・けど我慢しよ
今度はローカル変数とは異なり、メソッドをまたいで共有されていることがわかった。そして、インスタンスごとに異なった値をもつことができるということも証明された。
クラス変数
書き方:@@を前置
スコープ:そのクラスおよびそこから生成されるオブジェクト(インスタンス)の中ならどこからでも参照可能。
:sample.rb
class Nemui
@@feeling = "眠すぎ"
def nemu
puts @@feeling
end
end
nemui = Nemui.new
nemui.nemu #=>眠すぎ
グローバル変数
書き方:$を前置
スコープ:メソッドどころか、オブジェクトの壁ものりこえて有効。
最近よく聞くクエリについて
そもそも「クエリ」とは?
そもそも「クエリ」というのは、検索をおこなう際の検索条件のことだ。
一般に、データベースや表で何らかの検索をおこなう場合は、「検索対象となる項目」と「検索キーワード」を指定する必要がある。
たとえば、Excelで作った社員名簿という表があると想像してほしい。社員の中から「鈴木」という「名字」の社員を検索したい場合は、「検索対象となる項目」に「名字」を指定し、「検索キーワード」に「鈴木」という文字列を指定する。この場合は、「名字=鈴木」というのがクエリということになる。
この「名字=鈴木」という検索をおこなう際の「名字」にあたるものことを「パラメータ(変数)」といい、一方、「鈴木」にあたる文字列のことを「パラメータ(変数)の値」という。
まぁSQLでいうWHEREで指定する
カラムのことかな?(あんまり自信ない)
そもそもプログラミング言語って何?
プログラミングの概要
プログラムとはコンピュータにしてもらう
指示をまとめたもの。
私たちはプログラムを作ってコンピュータに実行させて、コンピュータに仕事をしてもらいます。
コンピュータは、内部では基本的に0と1だけの
2進数(バイナリ)で表現して動作しています。
しかし人間には機械語は難しいので、
普段私たちが使ってる言語に近い、決まった
文法や単語からなる文で指示を与えて、それをあとで2進数に訳して実行させるという方法が生まれた。
まさしくこれがプログラミングである。
ファイルの種類
①バイナリファイル
コンピュータが記録したファイルでもちろん2進数で書かれている。
②テキストファイル
2進数で決まった規則を使って、人間様のわかりやすくするための自然言語で表したもの。
また.txtなど、拡張子をつけて区別するが
プログラミング言語によってその拡張子は様々である。
また、そのためにファイル編集したりするもので、プログラムのコードを記述するためのものがテキストエディタと呼ばれるもの。
インタプリタとコンパイラ
コンピュータが認識できるのは2進数だと先ほど伝えたが、それを私たちの自然言語で書かれたプログラミング言語を機械語に翻訳する必要がある。
ソースコードを一行ずつ翻訳しながらプログラムを実行していく方法。このような種類のプログラミング言語をスクリプト言語と呼ぶ。
それを翻訳するためのソフトをインタプリタやシェルといいます。
Javascriptや、Pythonなどもそれに含まれる。
また、オブジェクト指向プログラミングを実現できるスクリプト言語がRubyやPHPなどになる。
ソースコードを全部一気に機械語に翻訳してから、機械語のファイルを実行する方法。
このような言語を一般的にコンパイル型言語などと呼ばれる。
プログラムのコードを機械語に翻訳することを
コンパイルという。
つまり、コンパイルするためのソフトウェアののことをコンパイラといいます。
代表例としてはC言語、C++、C#やFORTRANなどがそれにあたる。
またコンパイル型言語では、コード入力に使う言語と、実行ファイルは別である。
そのため、ソースコードを変更してもコンパイルしなければ変更は反映されない。
もちろん実行ファイルには機械語で書かれているので、その分だけ処理が高速になる。
実行ファイルの言語はOSやハードウェアそれぞれに合わせた機械語になっており、OSが異なると実行できなくなってくる。さらに言うと、実行ファイルだけだと元の内容はわからない。
ただその反面、機械語に変換された実行ファイルは配布するプログラムのもともとのコードの内容を秘密にしたいときは便利であるメリットもある。
どちらでもない言語、両方できる言語
プログラミング言語では、インタプリタかコンパイラかのどちらかがはっきりしない言語も存在する。例えばJava。
Javaはコードを記述後と、実行の前にJava専用の中間言語に変換する。
機械語に直接翻訳してないので、中間言語ファイルは特定のOSに依存しないでどのOSでも使用可能です。しかしJava中間言語に翻訳するためのソフトウェアが必要であり、そのようなソフトウェアがJavaランタイム(Javaを利用するためのソフトウェア)には組み込まれている
一見するとJavaのような中間言語生成のプログラミング言語はどのOSに依存しないので理想的なように見てるが、現状かなりの資金が必要でそのためオラクル社という大手IT企業が行っている。
また比較的新しい言語でいうと、両方コンパイルもスクリプト実行もできるのが多くなっており、例えばPythonはスクリプト型言語だが、コンパイルすることもできる。
Go言語やHaskellでは、コンパイルして実行することもできるし、ソースコードをそのまま実行することも可能。